基于Vision LLM把PDF转为Markdown的一款工具:vision-parse
主要功能:
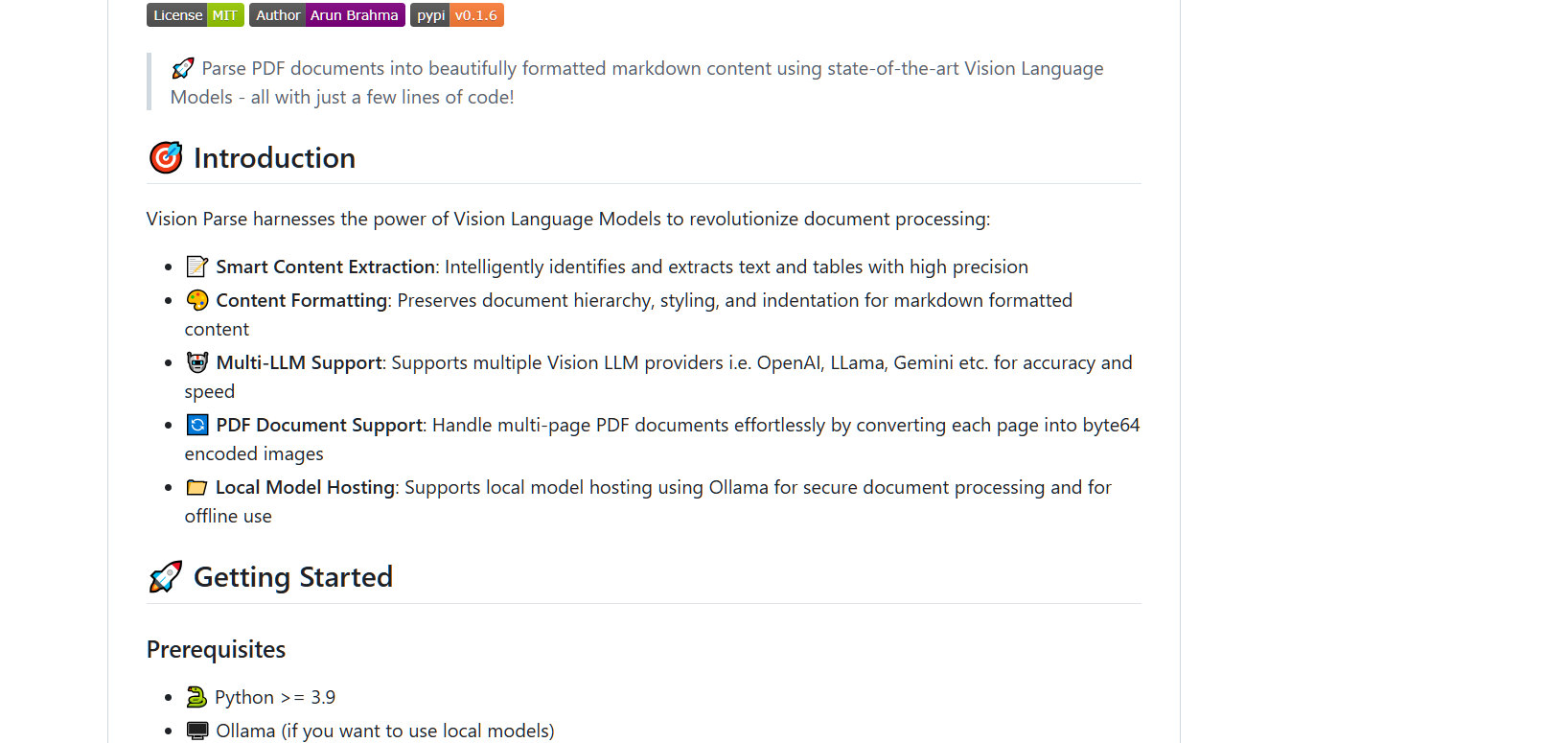
智能内容提取:能够准确识别和提取PDF中的文本和表格。
格式保持:在转换过程中,保持原始文档的层级结构和样式,确保输出的Markdown格式清晰易读。
多模型支持:兼容多种视觉语言模型,用户可以根据需求选择合适的模型进行文档处理。
PDF文档支持:能够处理多页PDF文档,并将其转换为base64编码的图像,便于进一步处理。
本地模型托管:支持使用Ollama进行本地模型部署,确保文档处理的安全性和隐私。
高精度提取:通过参数调整实现详细的内容提取,适合需要高精度数据的用户。
iamarunbrahma/vision-parse