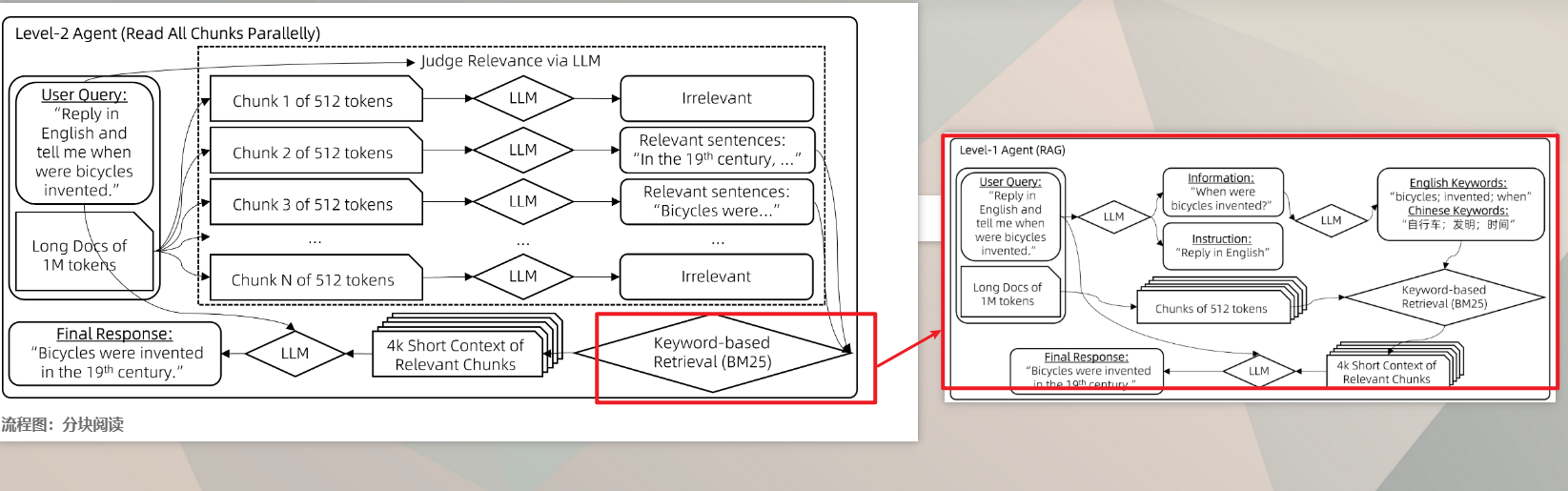
sinmucool 下面这篇文章给了一个优化基于RAG的AI知识库的思路 https://qwenlm.github.io/zh/blog/qwen-agent-2405/ 指导聊天模型将用户查询中的指令信息与非指令信息分开。 tokens 解析文档,然后按照tokens 分布来拆分块儿。 向量和关键词检索的结果统一起来给到LLM进行回答。 可以尝试利用已有的智能体来做推理步骤 上述步骤针对单个的PDF检索也有效